Eine offene AI Fabric: entwickelt für das, was Ihr Trainingsjob tatsächlich erlebt.
Der Engpass beim groß angelegten AI-Training ist das Netzwerk zwischen den GPUs. OcNOS-DC betreibt ein verlustfreies 800G RoCEv2 Fabric auf offenen Ethernet-Switches, heute abgestimmt auf GPU-Collectives und als Nächstes auf Ultra Ethernet: die offene Alternative zu einem geschlossenen Single-Vendor AI-Stack.
Architektur-Briefs herunterladen
Drei kurze Downloads, die tiefer gehen als diese Seite: die verlustfreie AI-Fabric-Architektur, die EVPN-VXLAN Data Center Referenz und DCI der nächsten Generation mit IPoDWDM.
OcNOS 800G Ethernet-basierte verlustfreie AI Fabric
Non-Blocking-RoCEv2-Fabric auf Tomahawk-4/5-Spines: SKU-Stufen, qualifizierte Plattformen und Deployment-Architektur.
Brief anfordernEVPN-VXLAN Data Center Fabric
Carrier-Grade-Leaf-Spine-Data-Center-Fabric: symmetrisches IRB, Type-2/Type-5-Routen, verteiltes Anycast-Gateway.
Brief anfordernDCI der nächsten Generation mit IPoDWDM
Reduzieren Sie die Transponder-Ebene: Betreiben Sie kohärente 400G/800G ZR und ZR+ Optiken direkt vom Router aus für den Data Center Interconnect.
Brief anfordernWas die Job-Abschlusszeit beeinflusst
Bei großer Skalierung zählt, wie schnell Jobs abgeschlossen werden und wie ausgelastet die GPUs bleiben, nicht der Switch-Durchsatz. Jedes Mal, wenn der Cluster zur Synchronisation pausiert, verursachen ungenutzte GPUs Kosten, daher darf das Fabric nichts verwerfen und muss im Moment des Entstehens auf Congestion reagieren.
OcNOS-DC legt jede Einstellung offen, sodass Ihr Team es auf realen GPU-Collective-Verkehr (NCCL, RCCL, oneCCL) abstimmen kann. Jedes der folgenden Muster zeigt das Problem, den Mechanismus, der es löst, und den Nutzen, den Sie erhalten.
→ DLB verlagert Flows in unter einer Millisekunde auf weniger ausgelastete Pfade.
→ GLB (OcNOS 7.1) verteilt die Last über das gesamte Fabric, nicht nur über den lokalen Hop.
→ DCQCN bremst Sender frühzeitig ab, bevor etwas überläuft.
→ PFC watchdog löst einen blockierten Port eigenständig.
→ Ultra Ethernet (UEC 1.0) verteilt einen einzelnen Flow gleichzeitig über alle Pfade.
→ Der Switch, den Sie heute kaufen, bleibt beim Eintreffen von UEC-NICs weiter nutzbar, ohne Austausch.
Referenz-Benchmark. DLB steigert die Fabric-Auslastung von etwa 55% bei Standard-Load-Balancing auf über 90% auf denselben Switches, ohne zusätzliche Uplinks. (Von der Industrie veröffentlichter Broadcom-Wert, reproduzierbar auf Tomahawk 4 und 5.)
DLB Deep-Dive →800G Spine-Leaf, verlustfrei von Ende zu Ende
Ein Standard-Leaf-Spine-Design (Clos): ein geroutetes eBGP-Underlay, gleichmäßig über alle Pfade verteilter Datenverkehr, verlustfreie Priority-Queues für GPU-Verkehr und ein separates Management-Netzwerk für Zero-Touch-Provisioning und Telemetrie. Bewegen Sie den Mauszeiger über einen Knoten, um Plattform, Portanzahl und Chip anzuzeigen.
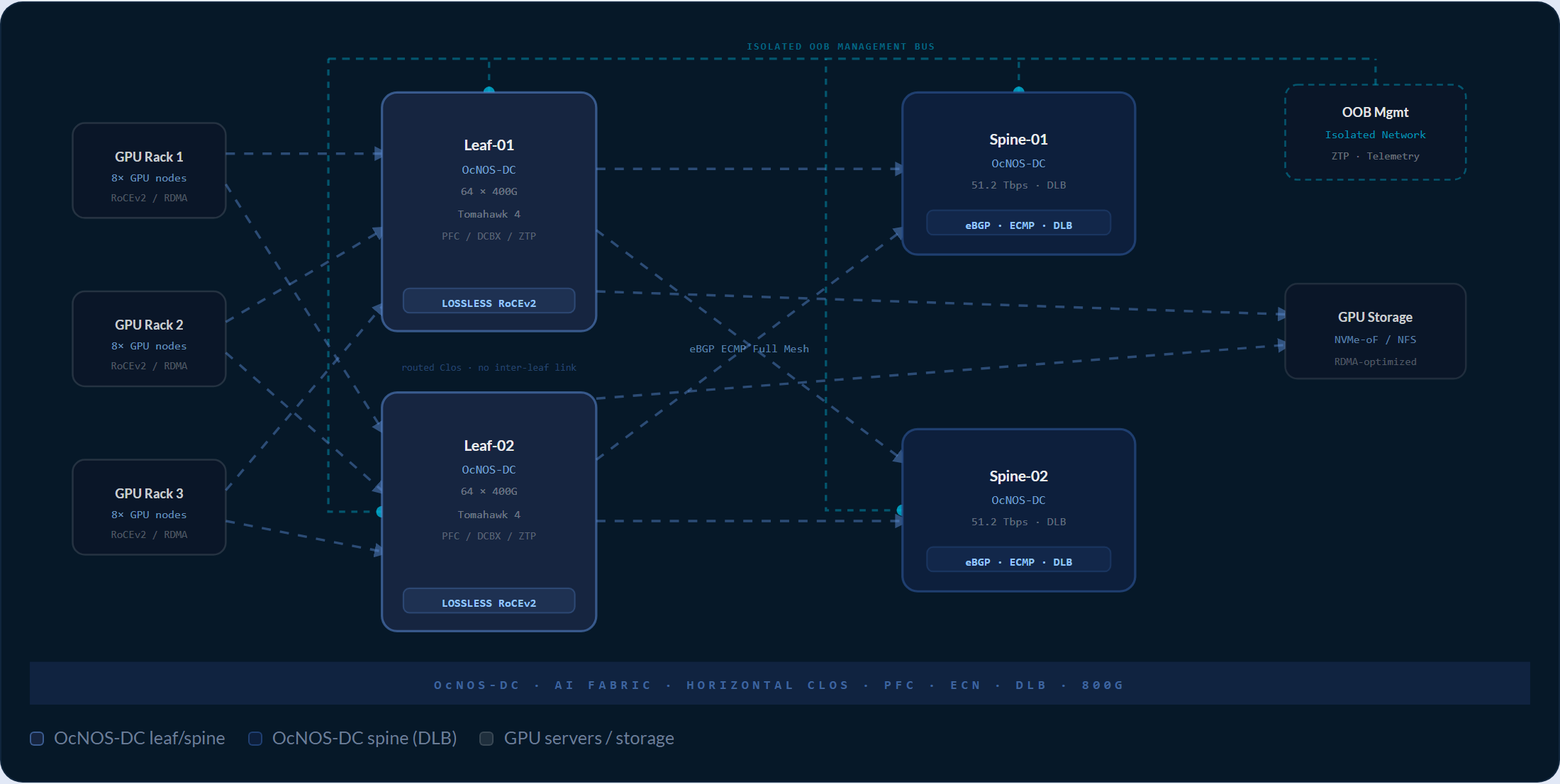
Fahren Sie über die Knoten, um Details zu Funktionen und Plattformen zu sehen · Vollständige HCL: 40+ validierte Plattformen unter ipinfusion.com/hcl
Validierte offene Switches
OcNOS-DC läuft auf Broadcom Tomahawk und Trident Switches von Edgecore und UfiSpace, sodass jede Plattform validiert, bestellbar und aus zweiter Quelle beziehbar ist.

Edgecore AIS800-64D
64 x 800G · 51.2 Tbps
QSFP-DD800 · breakout to 2x400G / 4x200G / 8x100G
Datasheet →
UfiSpace S9321-64E
64 x 800G · 51.2 Tbps
QSFP-DD800 · breakout to 2x400G / 4x200G / 8x100G
Datasheet →
Edgecore AS9736-64D
64 x 400G · 25.6 Tbps · deep buffer
QSFP56-DD 400G · breakout to 4x100G / 4x25G · DAC / AOC
Datasheet →Alle 40+ validierten Plattformen in der HCL ansehen →
Ein Anbieter für Software, Hardware und Support
Ein Vertrag, ein Ansprechpartner
Ein einziger IP Infusion Vertrag deckt die OcNOS-DC Software und die validierte Switch-Hardware gemeinsam ab, sodass es einen TAC und einen SLA gibt statt eines getrennten NOS- und Hardware-Anbieters. Ein 24/7 Support-Portal ist in den Tarifen Premium und Enterprise verfügbar.
Support-Details ansehenEine Konsole für das Fabric
IP Maestro ist ein Element-Management-System für OcNOS: Topologie, Störungen, Konfiguration und Software-Images über alle Switches hinweg per NETCONF, angesiedelt unterhalb Ihres bestehenden OSS. Validiert für 250 Geräte pro Instanz.
IP Maestro erkundenStreaming-Telemetrie und Zero-Touch
gNMI-Streaming-Telemetrie speist Prometheus und Grafana, DCBX überträgt automatisch die korrekten verlustfreien Einstellungen an jeden Server, und Zero-Touch-Provisioning bringt Switches bereits beim Booten konfiguriert in Betrieb.
Automatisierung entdeckenWo OcNOS-DC steht
Die meisten Optionen bieten heute dieselben Kernfunktionen: verlustfreies RoCEv2, Congestion Control, adaptives Routing, Ultra-Ethernet-Ausrichtung. Was wirklich unterscheidet, ist die Ausgestaltung des Vertrags: ein offenes Betriebssystem oder ein geschlossener Stack, offene oder geschlossene Hardware, Standard-Ethernet oder geschlossenes InfiniBand.
Jede Option zielt auf eine andere Priorität ab. OcNOS-DC überzeugt mit offener Hardware, einer Komplettlösung und ohne Lock-in.
Dimensionieren Sie Ihr GPU-Fabric in wenigen Minuten
Geben Sie Ihre GPU-Anzahl und NIC-Geschwindigkeit ein. Die AI Fabric Design Suite bildet daraus eine Leaf-Spine-Topologie, Switch- und Portanzahlen sowie eine Stückliste ab, die Sie direkt für ein Angebot verwenden können. Keine Tabellenkalkulation erforderlich.
OcNOS über das gesamte Rechenzentrum erweitern
AI ist ein Segment des Rechenzentrums. Dasselbe OcNOS-Image erstreckt sich auf Compute, Storage und entfernte Standorte: dasselbe NOS, dieselbe CLI, derselbe Support.
Häufig gestellte Fragen
OcNOS 800G Ethernet-basierte verlustfreie AI Fabric
Kurzes Formular. Ihr PDF wird unmittelbar nach dem Absenden heruntergeladen.
✓ Ihr PDF wird in einem neuen Tab geöffnet…
Falls es sich nicht geöffnet hat, nutzen Sie den untenstehenden Link.
Solution_Brief-OcNOS_800G_Ethernet-Based_Lossless_AI_Fabric.pdfEVPN-VXLAN Data Center Fabric
Kurzes Formular. Ihr PDF wird unmittelbar nach dem Absenden heruntergeladen.
✓ Ihr PDF wird in einem neuen Tab geöffnet…
Falls es sich nicht geöffnet hat, nutzen Sie den untenstehenden Link.
OcNOS-modernize-your-data-center-EVPN-VxLAN_Solution-Brief.pdfDCI der nächsten Generation mit IPoDWDM
Kurzes Formular. Ihr PDF wird unmittelbar nach dem Absenden heruntergeladen.
✓ Ihr PDF wird in einem neuen Tab geöffnet…
Falls es sich nicht geöffnet hat, nutzen Sie den untenstehenden Link.
solution-brief-next-gen-dci-ipodwdm.pdfAI-Fabric- & DC-Deployments
Produktive AI-Cluster und Data-Center-Fabrics, die OcNOS-DC auf Broadcom Tomahawk 4/5 betreiben.

NTT DATA ist eine Partnerschaft mit IP Infusion eingegangen, um disaggregierte Open-Networking-Lösungen auf den Markt zu bringen, und bietet OcNOS-basierte Cell Site Router, Routed…

Scott Data hat OcNOS mit Open-Networking-Hardware von UfiSpace, Edgecore Networks und Celestica implementiert und damit Legacy-Vendor-Stacks in seinem gesamten…
Madeo Consultant, ein in Frankreich ansässiger Rechenzentrums-Systemintegrator, hat Cisco Nexus- und Catalyst-Switches durch IP Infusion OcNOS auf Edgecore… ersetzt
Prosoluce, ein französischer ISP und Anbieter von Managed Services, rüstete seinen Core auf ein 100G-EVPN-VXLAN-Backbone mit IP Infusion OcNOS auf…
Passend aus dem Blog
Das AI Network Decision Framework: GPU-Fabric für Geschwindigkeit, ROI, strategische Freiheit
Framework auf Käuferseite für Entscheidungen zur GPU-Fabric mit RoCEv2 und offener Hardware
Beitrag lesen →OcNOS 7.0 für Rechenzentren: AI Fabric, 800G-Plattformen, EVPN-VXLAN im großen Maßstab
800G-AI-Fabric-Features und Tomahawk-5-Plattformen, die in OcNOS 7.0 ausgeliefert werden
Beitrag lesen →OcNOS 7.0: What's New for AI, Transport, and Cloud
Hebt verlustfreien RoCEv2-Transport mit PFC für GPU-Cluster hervor
Beitrag lesen →OcNOS 6.6 für Rechenzentren: AI Fabric PFC/ETS, EVPN Policy, 400G
Verlustfreie PFC/ETS-DCB-Features, die OcNOS-AI-Fabric-Deployments zugrunde liegen
Beitrag lesen →