AI Fabric 拓撲:Rail-Optimized 與調度式設計
The shape of your fabric decides the shape of your training job. This page lays out the reference topologies OcNOS-DC ships against, from a rail-optimized single pod, through a scheduled 3-stage Clos, to coherent multi-DC DCI, sized in concrete port-counts on Broadcom Tomahawk 4 and Tomahawk 5 hardware.
按 GPU 數量選擇,而非按流行術語
AI fabric 拓撲只有一個使命:保持 every GPU 的出向連結在集合運算期間達到飽和,同時不產生尾端延遲的離群值。合適的拓撲是能夠針對您的 GPU 數量實現此目標的最小規模拓撲,並具備擴展至下一更大規模的回退路徑。以下為 OcNOS-DC 目前支援的三種參考設計,並附有具體的埠計算。
正在為自己的叢集進行容量規劃? The AI Fabric Design Suite 可提供快速的初步測算:它可測算出一個 無阻塞兩層架構 假設條件下的 leaf-spine pod 每個 GPU 一片 fabric NIC,並在進入三層規模時予以提示。下面的參考設計採用 same 非阻塞的leaf/spine計算,並將其擴展為大規模的3級Clos,從而使交換器數量與工具相吻合。 Rail-optimized here is the wiring discipline of an 8-NIC GPU server (one rail per leaf, so intra-rail AllReduce stays on the leaf) layered on that non-blocking fabric: it changes traffic locality, not the switch count. Use the tool for a ballpark; use these designs for the build.
入門級無阻塞 pod
在小型 spine 層之上部署一行軌道對齊 leaf。兩層摺疊式 Clos,1:1 無阻塞。
軌道最佳化的兩層 pod
採用軌道對齊 leaf 加 1:1 無阻塞 spine。軌道內 AllReduce 保持在 leaf 上完成;跨軌道流量經由 spine。標準的單 pod 可擴展單元。
3 級 Clos
Leaf, spine, super-spine. Each 1,024-GPU pod is 1:1 non-blocking; a super-spine plane scales across pods. DLB at every tier; GLB end-to-end on the OcNOS 7.1 train.
規模化 3 級 Clos
帶有超級骨幹平面的多 Pod 三級 Clos。專為萬億參數訓練級別設計。
軌道最佳化單 Pod
每臺 GPU 伺服器配備 8 個 NIC,每個對應一條 "rail",即專用 xCCL (NCCL / RCCL / oneCCL) 集體通信通道。每條 rail 擁有獨立的專用葉交換機、因此每臺伺服器的 8 個 NIC 都落到不同的葉交換機上。跨 rail-N 的 AllReduce 保持在 leaf-N 內部。主導集體通信模式不會對 spine 產生東西向壓力。
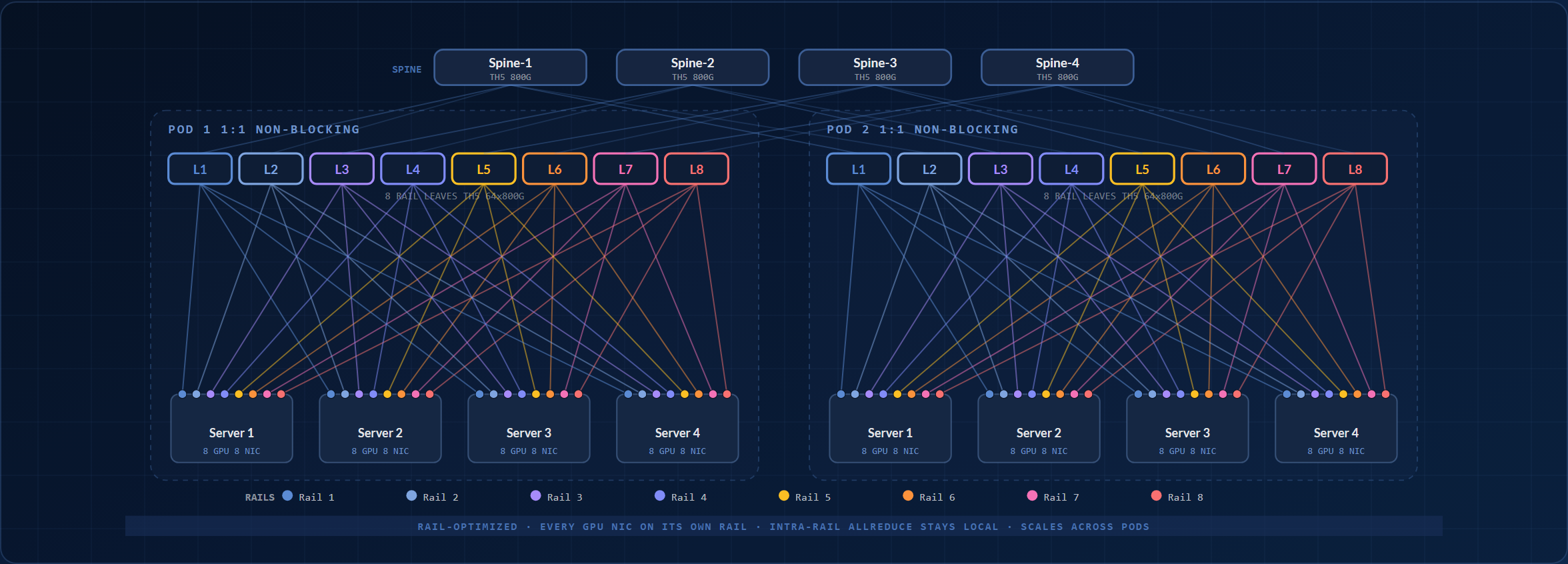
OcNOS 組件: BGP-unnumbered L3 underlay, RoCEv2 lossless (PFC + ECN) on every leaf, DLB at the spine tier. Built on HCL-listed hardware: the 800G scalable unit uses TH5 64×800G leaves and spines (Edgecore AIS800-64D or UfiSpace S9321-64E); the entry 256-GPU pod uses Edgecore AS9736-64D (TH4, 64×400G).
調度式對比 Rail-Aligned:規模化時的變化
Rail-optimized stops scaling somewhere between 1k and 2k GPUs: you run out of leaf radix, or the spine tier becomes too oversubscribed. Above that, most modern AI fabrics move to a 3-stage Clos: leaf, spine, super-spine. The hard part on a Clos is spreading flows evenly so no link becomes a hot spot. Approaches run from per-flow ECMP, through adaptive (dynamic) load balancing, to per-packet spray, the model Ultra Ethernet uses with reordering handled at the NIC. A separate family, cell-based scheduled fabrics such as Broadcom DDC, segments traffic into cells and schedules it inside the fabric. OcNOS keeps the GPU plane balanced with DLB today and adds fabric-wide GLB on the 7.1 train, and is UEC-ready as UEC NICs arrive.
3-Stage Clos Scheduled Fabric: 4,096-16,384 GPUs
Three tiers: leaf, spine, super-spine. Any two GPUs are at most four switch hops apart; same-leaf and same-pod peers are closer. Non-blocking within a pod, with the super-spine plane setting the cross-pod ratio. DLB at every hop, GLB across the full path on the OcNOS 7.1 train, UEC packet-spray on UEC-capable NICs. The diagram is schematic: it draws a reduced tier count; the 4,096-GPU build is 128 leaves / 64 spines / 32 super-spines on TH5 800G.
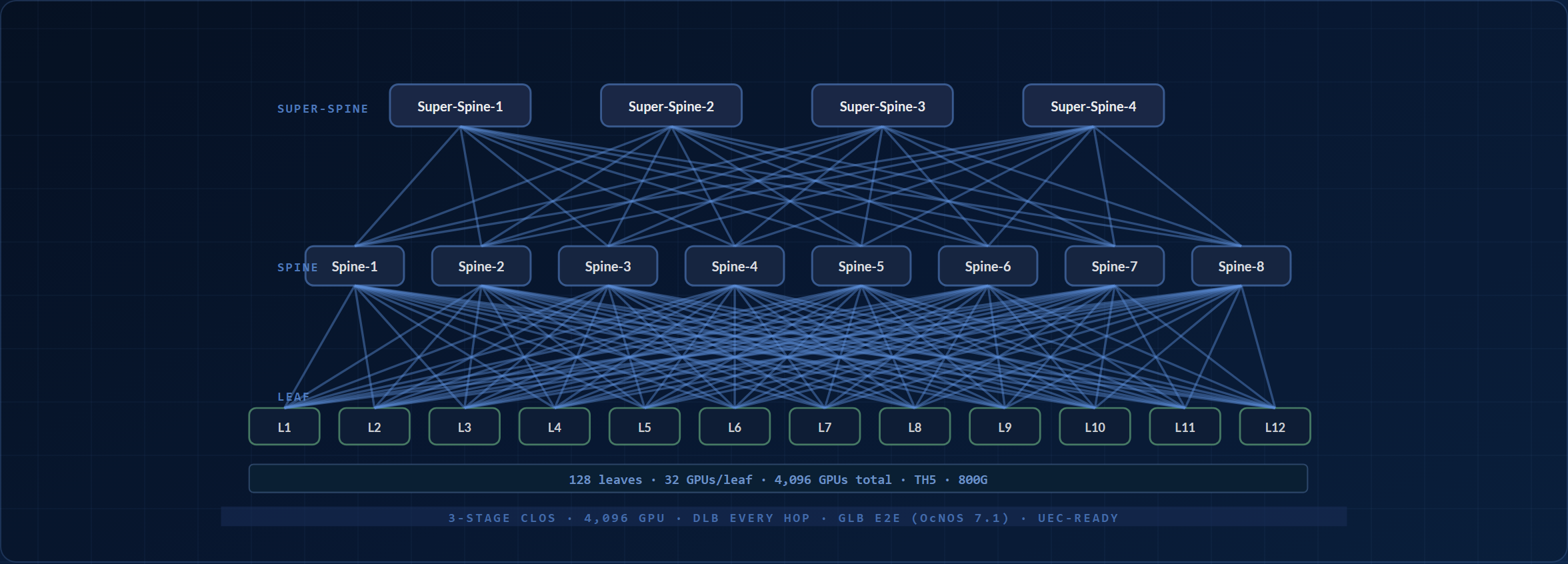
OcNOS 組件: eBGP-unnumbered L3 underlay, RoCEv2 lossless (PFC + ECN), DLB at every tier, GLB end-to-end on the OcNOS 7.1 train, and gNMI streaming telemetry to your observability stack. Built on HCL-listed TH5 64×800G chassis throughout.
Subscription is a dial, not a fixed rule. These counts make each 1,024-GPU pod 1:1 non-blocking and use a cost-optimized ~2:1 super-spine for cross-pod traffic, the rail-optimized approach hyperscale Ethernet fabrics rely on (published large-scale designs oversubscribe the top tier far more, because collective traffic stays pod-local). Want maximal any-to-any headroom instead? A fully non-blocking 1:1 build is 128 / 128 / 64 at 4,096 GPUs and 512 / 512 / 256 at 16,384; only the spine and super-spine counts change. Model either in the AI Fabric Design Suite.
適用於分布式訓練的多 DC 與 DCI
When a single training run spans more than one data hall, increasingly common for trillion-parameter models, the fabric extends across the WAN. OcNOS-DC supports 400G ZR / ZR+ coherent optics directly on the spine for transponder-free DCI across sites.
多資料中心 AI 網路:相干 DCI
Two AI data centers stitched together with 400G ZR/ZR+ coherent optics on the spine. The underlying 3-stage Clos in each site is unchanged.
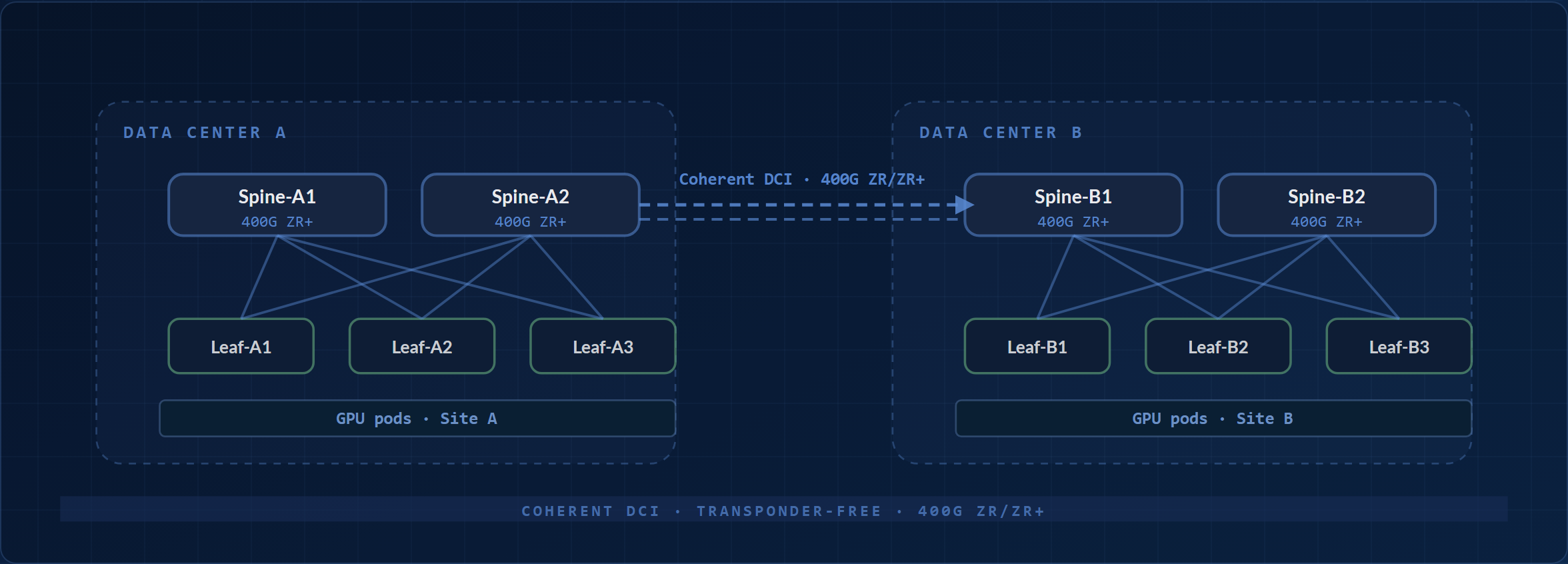
OcNOS 組件: 400G ZR/ZR+ pluggable coherent optics on a DWDM-capable spine or border-leaf port, with gNMI telemetry across sites. No external transponders required. Reach: 400ZR to roughly 120 km amplified; OpenZR+ reaches farther on oFEC.
設計經驗法則
- 使拓撲與 GPU 數量相匹配。 最小規模 pod(不超過單臺 leaf 的 NIC 基數):僅用 rail-only 即可。單 pod 規模:採用 rail 最佳化的 leaf-spine。多 pod 規模:三級 Clos 是唯一能在不犧牲超額訂閱的前提下實現擴展的設計。
- AI 平面始終保持 1:1 訂閱比。 儲存與 CPU 機架可承受更高的超額訂閱比率。GPU 平面則不應如此。
- 軌道數應依據 xCCL 規劃,而非布線便利。 對於 8-NIC GPU 伺服器,8 軌是當前的事實標準。請勿將多條軌合併到更少的 leaf 上。
- 按功耗和密度選擇晶片,而非按品牌標識。 TH4(25.6T)和 TH5(51.2T)是主力晶片;二者之間的取捨在於機架功耗和 breakout 線纜成本。
- 在設計階段就為 GLB / UEC 做好規劃。 從第一天起就將遙測平面構建到位,即便是在 7.0 fabric 上,這樣 OcNOS 7.1 GLB 升級便純粹是一次軟體操作。詳見 GLB and Ultra Ethernet.
- 對照 HCL 進行驗證。 此處的每個參考方案均構建於所列硬體之上,詳見 OcNOS 硬體兼容性列表;從那裡開始即可獲得一流支持。
AI fabric topology FAQ
What is a rail-optimized topology, and how is it different from rail-only?
How many GPUs can a 3-stage Clos scale to?
Should I use Tomahawk 4 or Tomahawk 5?
Do I need InfiniBand, or is Ethernet enough?
Where does scale-up end and scale-out begin?
正在設計您的 AI fabric?我們與您一起完成埠數量的測算。
預約架構評審 →Design the whole AI fabric with OcNOS
From the business case to the port-count maths, pick up wherever you are in the build.
深入了解,隨身帶走。
產品規格書,以及內容比本頁更為深入的簡明技術下載資料。
OcNOS-DC 規格書
完整的 OcNOS-DC 規格:EVPN-VXLAN 與 Ethernet for AI 功能集、軟體 SKU、支援的硬體平台,以及解決方案訂購指南。
取得規格書OcNOS 800G 無損 AI Fabric
基於 Broadcom Tomahawk 4/5 spine 的無阻塞 RoCEv2 fabric:SKU 級別、經驗證的平台以及部署架構。
取得簡報EVPN-VXLAN 資料中心網路
carrier-grade 的 leaf-spine data center fabric:對稱 IRB、Type-2/Type-5 路由,以及分散式 anycast 閘道。
取得簡報OcNOS 800G 無損 AI Fabric
表單簡短。提交後您的 PDF 將立即在新標籤頁中打開。
✓ 正在新標籤頁中打開您的 PDF……
如果未能自動打開,請使用下方連結。
EVPN-VXLAN 資料中心網路
表單簡短。提交後您的 PDF 將立即在新標籤頁中打開。
✓ 正在新標籤頁中打開您的 PDF……
如果未能自動打開,請使用下方連結。