AI Fabric 토폴로지: Rail-Optimized 및 Scheduled 설계
The shape of your fabric decides the shape of your training job. This page lays out the reference topologies OcNOS-DC ships against, from a rail-optimized single pod, through a scheduled 3-stage Clos, to coherent multi-DC DCI, sized in concrete port-counts on Broadcom Tomahawk 4 and Tomahawk 5 hardware.
유행어가 아닌 GPU 수로 선택하세요
AI 패브릭 토폴로지의 임무는 하나입니다: every GPU의 아웃바운드 링크가 집합 연산 중에 포화되더라도 tail-latency 이상값을 발생시키지 않아야 합니다. 적절한 토폴로지란 고객의 GPU 수에 대해 이를 구현하는 최소 구성이며, 다음 규모로 확장하기 위한 폴백 경로를 갖춘 것입니다. 아래에서는 OcNOS-DC가 현재 지원하는 세 가지 레퍼런스 디자인을 구체적인 포트 계산과 함께 소개합니다.
직접 클러스터를 사이징하고 계십니까? The AI Fabric Design Suite 은 신속한 초기 산정을 제공합니다. 즉, 다음을 산정합니다 논블로킹 2 계층 구성 다음을 가정한 leaf-spine 포드 GPU당 fabric NIC 1개, 그리고 3계층 규모로 넘어갈 때 이를 표시합니다. 아래의 참조 설계는 다음을 사용합니다. same non-blocking leaf/spine 계산을 수행하고 이를 대규모 3단계 Clos로 확장하여, 스위치 수량이 도구와 일치하도록 합니다. Rail-optimized here is the wiring discipline of an 8-NIC GPU server (one rail per leaf, so intra-rail AllReduce stays on the leaf) layered on that non-blocking fabric: it changes traffic locality, not the switch count. Use the tool for a ballpark; use these designs for the build.
엔트리 논블로킹 파드
소규모 스파인 계층 위에 레일 정렬형 리프를 배치한 랙 1열. 2계층 폴디드(folded) Clos, 1:1 논블로킹.
Rail 최적화 2계층 파드
1:1 논블로킹 spine을 갖춘 rail 정렬 leaf 구조. rail 내부 AllReduce는 leaf에 머물고, rail 간 트래픽은 spine을 거칩니다. 표준 단일 파드 확장 단위입니다.
3단 Clos
Leaf, spine, super-spine. Each 1,024-GPU pod is 1:1 non-blocking; a super-spine plane scales across pods. DLB at every tier; GLB end-to-end on the OcNOS 7.1 train.
확장형 3단 Clos
슈퍼스파인 플레인을 갖춘 멀티 파드 3단계 Clos. 조 단위 파라미터 학습 클래스에 맞게 설계되었습니다.
Rail-Optimized 단일 Pod
각 GPU 서버는 NIC 8개를 가지며 각각이 "레일" (전용 xCCL (NCCL / RCCL / oneCCL) 컬렉티브 채널) 에 대응합니다. 각 레일은 자체 전용 리프를 가지므로 모든 서버의 NIC 8개가 서로 다른 리프에 도착합니다. 레일 N 간의 AllReduce는 리프 N 내부에 머무릅니다. 지배적 컬렉티브 패턴에서는 스파인에 east-west 부하가 발생하지 않습니다.
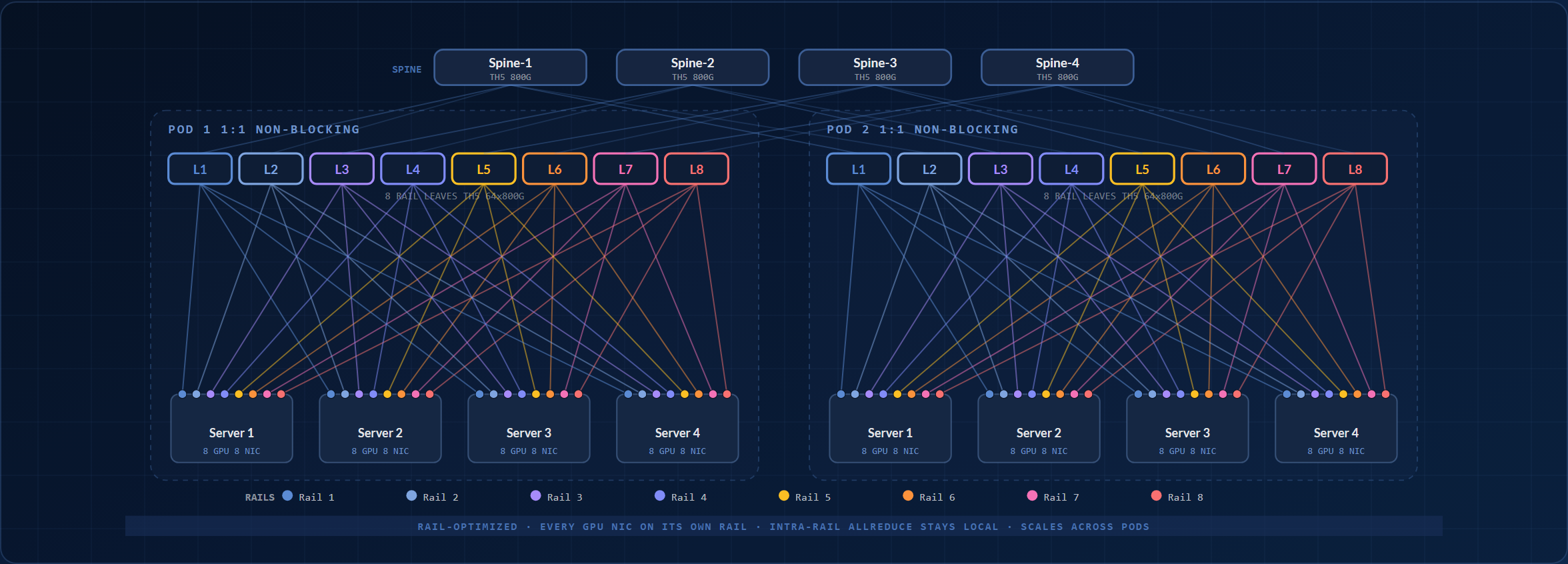
OcNOS 구성 요소: BGP-unnumbered L3 underlay, RoCEv2 lossless (PFC + ECN) on every leaf, DLB at the spine tier. Built on HCL-listed hardware: the 800G scalable unit uses TH5 64×800G leaves and spines (Edgecore AIS800-64D or UfiSpace S9321-64E); the entry 256-GPU pod uses Edgecore AS9736-64D (TH4, 64×400G).
Scheduled vs Rail-Aligned: 대규모 환경에서 달라지는 점
Rail-optimized stops scaling somewhere between 1k and 2k GPUs: you run out of leaf radix, or the spine tier becomes too oversubscribed. Above that, most modern AI fabrics move to a 3-stage Clos: leaf, spine, super-spine. The hard part on a Clos is spreading flows evenly so no link becomes a hot spot. Approaches run from per-flow ECMP, through adaptive (dynamic) load balancing, to per-packet spray, the model Ultra Ethernet uses with reordering handled at the NIC. A separate family, cell-based scheduled fabrics such as Broadcom DDC, segments traffic into cells and schedules it inside the fabric. OcNOS keeps the GPU plane balanced with DLB today and adds fabric-wide GLB on the 7.1 train, and is UEC-ready as UEC NICs arrive.
3-Stage Clos Scheduled Fabric: 4,096-16,384 GPUs
Three tiers: leaf, spine, super-spine. Any two GPUs are at most four switch hops apart; same-leaf and same-pod peers are closer. Non-blocking within a pod, with the super-spine plane setting the cross-pod ratio. DLB at every hop, GLB across the full path on the OcNOS 7.1 train, UEC packet-spray on UEC-capable NICs. The diagram is schematic: it draws a reduced tier count; the 4,096-GPU build is 128 leaves / 64 spines / 32 super-spines on TH5 800G.
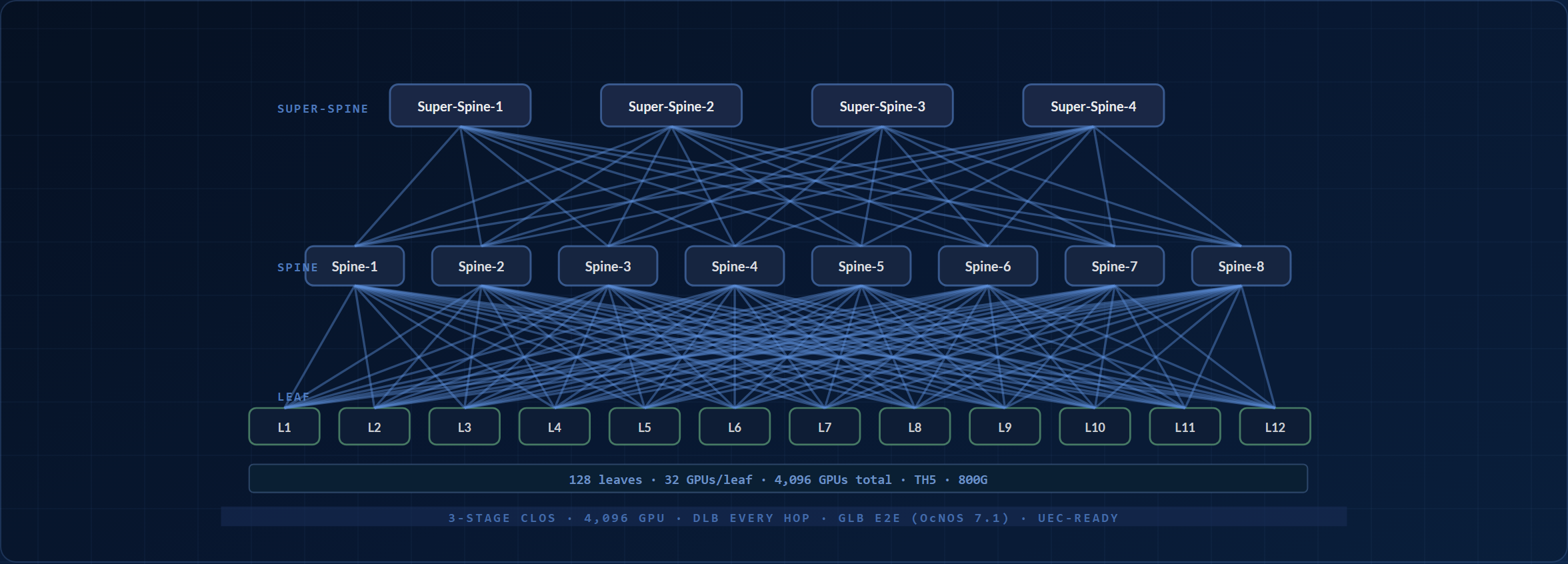
OcNOS 구성 요소: eBGP-unnumbered L3 underlay, RoCEv2 lossless (PFC + ECN), DLB at every tier, GLB end-to-end on the OcNOS 7.1 train, and gNMI streaming telemetry to your observability stack. Built on HCL-listed TH5 64×800G chassis throughout.
Subscription is a dial, not a fixed rule. These counts make each 1,024-GPU pod 1:1 non-blocking and use a cost-optimized ~2:1 super-spine for cross-pod traffic, the rail-optimized approach hyperscale Ethernet fabrics rely on (published large-scale designs oversubscribe the top tier far more, because collective traffic stays pod-local). Want maximal any-to-any headroom instead? A fully non-blocking 1:1 build is 128 / 128 / 64 at 4,096 GPUs and 512 / 512 / 256 at 16,384; only the spine and super-spine counts change. Model either in the AI Fabric Design Suite.
분산 학습을 위한 멀티 DC 및 DCI
When a single training run spans more than one data hall, increasingly common for trillion-parameter models, the fabric extends across the WAN. OcNOS-DC supports 400G ZR / ZR+ coherent optics directly on the spine for transponder-free DCI across sites.
멀티 DC AI 패브릭: 코히어런트 DCI
Two AI data centers stitched together with 400G ZR/ZR+ coherent optics on the spine. The underlying 3-stage Clos in each site is unchanged.
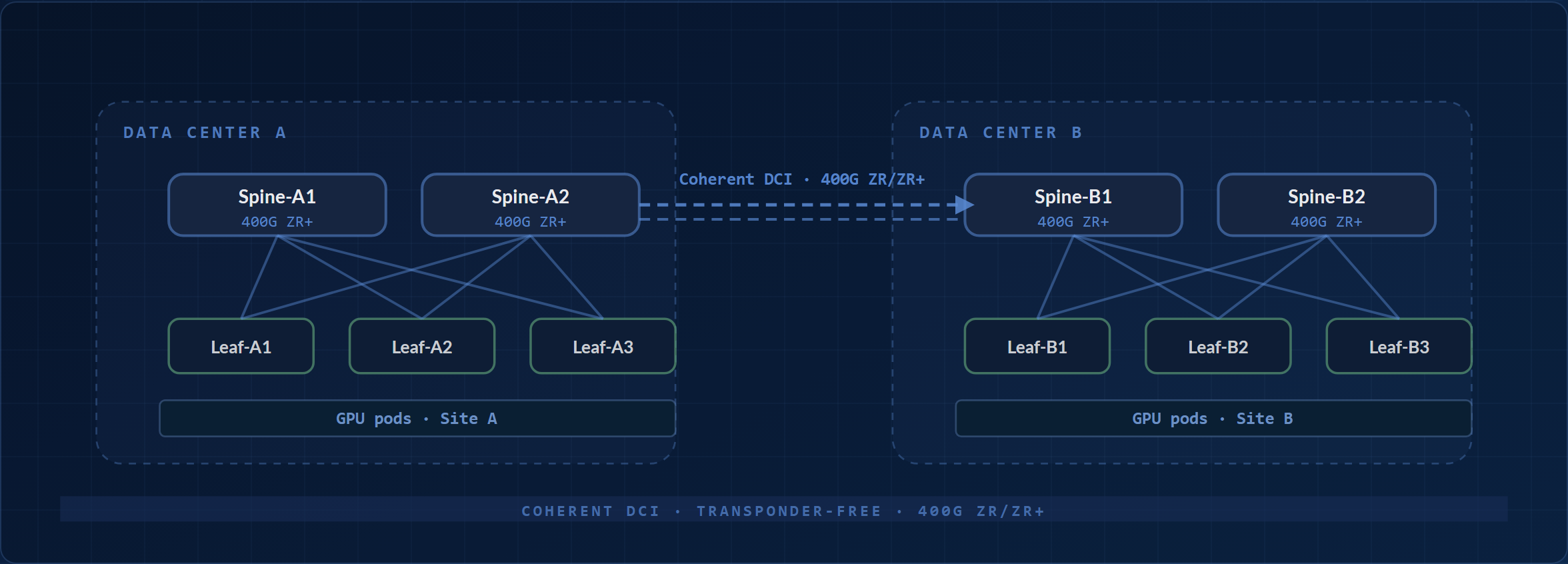
OcNOS 구성 요소: 400G ZR/ZR+ pluggable coherent optics on a DWDM-capable spine or border-leaf port, with gNMI telemetry across sites. No external transponders required. Reach: 400ZR to roughly 120 km amplified; OpenZR+ reaches farther on oFEC.
설계 경험 법칙
- 토폴로지를 GPU 수에 맞추세요. 가장 작은 파드(단일 리프의 NIC radix 미만): rail-only로 충분합니다. 단일 파드 규모: rail-optimized 리프-스파인. 멀티 파드: 3-스테이지 Clos는 오버서브스크립션 타협 없이 확장할 수 있는 유일한 설계입니다.
- AI 플레인에서 항상 1:1 subscription. 스토리지 및 CPU 랙은 더 높은 oversubscription 비율로 운영할 수 있습니다. GPU 플레인은 그래서는 안 됩니다.
- 레일 수는 케이블링 편의가 아니라 xCCL을 기준으로 결정합니다. 8 rail은 현재 8-NIC GPU 서버의 사실상 표준입니다. rail을 더 적은 수의 leaf로 통합하지 마세요.
- 배지가 아닌 전력과 밀도로 실리콘을 선택하십시오. TH4(25.6T)와 TH5(51.2T)가 핵심 주력 제품이며, 둘 사이의 선택은 랙 전력과 breakout 케이블 비용에 달려 있습니다.
- 설계 단계에서 GLB / UEC를 계획하십시오. 7.0 패브릭에서도 첫날부터 텔레메트리 플레인을 구축해 두면, OcNOS 7.1 GLB 업그레이드가 순수한 소프트웨어 단계만으로 끝납니다. 참고: GLB and Ultra Ethernet.
- HCL 기준으로 검증하십시오. 여기 모든 레퍼런스는 다음에 나열된 하드웨어 기반으로 구축되었습니다 OcNOS 하드웨어 호환성 목록; 거기서부터 최상급 지원을 선택하십시오.
AI fabric topology FAQ
What is a rail-optimized topology, and how is it different from rail-only?
How many GPUs can a 3-stage Clos scale to?
Should I use Tomahawk 4 or Tomahawk 5?
Do I need InfiniBand, or is Ethernet enough?
Where does scale-up end and scale-out begin?
AI 패브릭을 설계 중이신가요? 포트 수 계산을 함께 진행하겠습니다.
아키텍처 리뷰 예약하기 →Design the whole AI fabric with OcNOS
From the business case to the port-count maths, pick up wherever you are in the build.
더 깊이 살펴보십시오. 자료를 소장하십시오.
제품 데이터시트와 이 페이지보다 한층 더 깊이 있는 간결한 기술 다운로드 자료입니다.
OcNOS-DC 데이터시트
OcNOS-DC 전체 사양: EVPN-VXLAN 및 Ethernet for AI 기능 세트, 소프트웨어 SKU, 지원 하드웨어 플랫폼, 솔루션 주문 가이드.
Datasheet 받기OcNOS 800G 무손실 AI Fabric
Broadcom Tomahawk 4/5 스파인 기반의 논블로킹 RoCEv2 fabric: SKU 등급, 검증된 플랫폼, 도입 아키텍처를 다룹니다.
브리프 받기EVPN-VXLAN 데이터센터 패브릭
carrier-grade leaf-spine data center fabric: 대칭 IRB, Type-2/Type-5 라우트, 분산 anycast 게이트웨이.
브리프 받기OcNOS-DC 데이터시트
간단한 양식입니다. 제출하면 PDF가 즉시 새 탭에서 열립니다.
✓ 새 탭에서 PDF를 여는 중입니다…
열리지 않았다면 아래 링크를 이용해 주십시오.
OcNOS 800G 무손실 AI Fabric
간단한 양식입니다. 제출하면 PDF가 즉시 새 탭에서 열립니다.
✓ 새 탭에서 PDF를 여는 중입니다…
열리지 않았다면 아래 링크를 이용해 주십시오.
EVPN-VXLAN 데이터센터 패브릭
간단한 양식입니다. 제출하면 PDF가 즉시 새 탭에서 열립니다.
✓ 새 탭에서 PDF를 여는 중입니다…
열리지 않았다면 아래 링크를 이용해 주십시오.