RoCEv2:適用於 AI fabric 的無損乙太網
RDMA over Converged Ethernet v2 正是在現代 AI fabric 上承載 GPU 集合通訊流量的技術。OcNOS 在支援的 400G 和 800G 開放硬體上實現了完整的 RoCEv2 工具集(PFC、ECN/DCQCN、自適應負載平衡以及按優先權的遙測)。
AI Fabric 軌道拓撲
一段緊湊的 rail 切片:兩臺 spine 與兩臺 leaf 在四塊 GPU 之間承載 RoCEv2。擁塞時 PFC 暫停幀逐跳傳遞,同時 ECN 標記大象流,以便在源端觸發 DCQCN 反應。
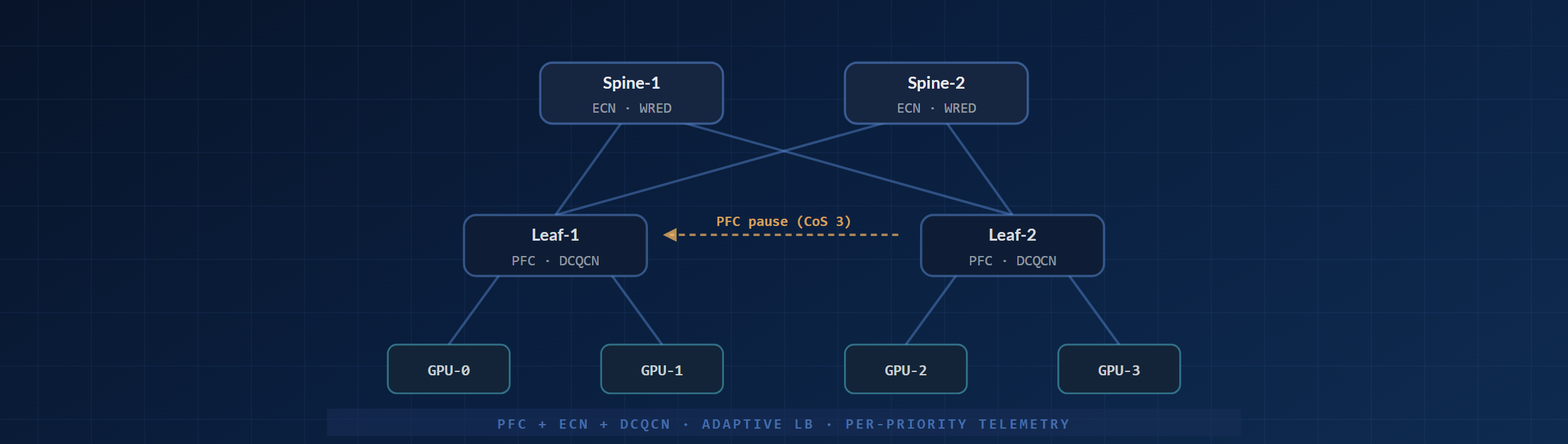
為什麼 RoCEv2 對 AI fabric 至關重要
GPU 集合通信(all-reduce、all-gather、all-to-all)會產生 大象流 這些流量會使單一 fabric 路徑飽和,並要求接近零丟包以維持訓練作業的效率。在 400G RoCEv2 鏈路上丟失一個封包,受影響的 NIC 便會重傳整個 RDMA 傳送視窗,其代價可按數秒的 GPU 閒置時間衡量。RoCEv2 將 leaf-spine fabric 轉變為適用於這些工作負載的 lossless transport,包含三大支柱:PFC(Priority Flow Control)、ECN(Explicit Congestion Notification)與 DCQCN(Data Center Quantized Congestion Notification)。若要為您的 GPU 叢集評估交換器層級與連接埠數量,請使用 AI Fabric 規模估算工具.
OcNOS RoCEv2 實現方案
按優先級暫停
在可配置優先級隊列上運行 802.1Qbb PFC,並配合看門狗定時器檢測死鎖狀態,在其傳播之前自動恢復。
自適應標記
按隊列進行基於 WRED 的 ECN 標記,並提供 DCQCN 反應點反饋。針對 xCCL (NCCL / RCCL / oneCCL) 集體通信工作負載調優的預設值;適用於自定義 RDMA 棧提供參數化覆蓋。
自適應 flowlet
動態負載均衡(DLB)在亞毫秒級間隔內於鏈路飽和時對 flowlet 重新分配。消除了損害對稱拓撲的靜態哈希衝突。
按優先級隊列統計
用於隊列深度、PFC 暫停計數、ECN 標記報文及微突發檢測的 gNMI 流式傳感器,以 1 秒粒度導出。
軌道最佳化(rail-optimized)網路
Validated for rail-aligned and scheduled-fabric topologies. Recipes for 256-4,096 GPU clusters using off-the-shelf 400G and 800G open switches.
無損驗證
提供 CLI 診斷工具,端到端驗證已知良好的無損配置:PFC 餘量計算、ECN 閾值合理性檢查,以及合成的 incast 測試。
OcNOS 為您帶來什麼
- 開放的硬體選擇。 在 UfiSpace、Edgecore、Wedge 或 Celestica 平台上以同一 NOS 鏡像運行 RoCEv2:fabric 層無廠商鎖定。
- 第一天即具備同等功能。 自適應 LB、DCQCN 調優和 ASIC 原生遙測並非付費附加項。它們是 OcNOS-DC 基礎許可的一部分。
- 參考設計。 針對主流 AI fabric 拓撲的已驗證配置:我們公開配置檔案及測試結果。
- 工程訪問權限。 高級支持層級包含在 fabric 搭建期間與 OcNOS RoCEv2 團隊的直接溝通。
正在建置或擴展 AI 網路架構?
申請技術演示 →常見問題
什麼是 RoCEv2?
RoCEv2與RoCEv1有何區別?
RoCEv2 是否需要 lossless 網路?
RoCEv2使用哪個UDP連接埠?
RoCEv2 與 InfiniBand 相比如何?
深入了解,隨身帶走。
產品規格書,以及內容比本頁更為深入的簡明技術下載資料。
OcNOS-DC 規格書
完整的 OcNOS-DC 規格:EVPN-VXLAN 與 Ethernet for AI 功能集、軟體 SKU、支援的硬體平台,以及解決方案訂購指南。
取得規格書OcNOS 800G 無損 AI Fabric
基於 Broadcom Tomahawk 4/5 spine 的無阻塞 RoCEv2 fabric:SKU 級別、經驗證的平台以及部署架構。
取得簡報EVPN-VXLAN 資料中心網路
carrier-grade 的 leaf-spine data center fabric:對稱 IRB、Type-2/Type-5 路由,以及分散式 anycast 閘道。
取得簡報OcNOS 800G 無損 AI Fabric
表單簡短。提交後您的 PDF 將立即在新標籤頁中打開。
✓ 正在新標籤頁中打開您的 PDF……
如果未能自動打開,請使用下方連結。
EVPN-VXLAN 資料中心網路
表單簡短。提交後您的 PDF 將立即在新標籤頁中打開。
✓ 正在新標籤頁中打開您的 PDF……
如果未能自動打開,請使用下方連結。
Design the whole AI fabric with OcNOS
From the business case to the port-count maths, pick up wherever you are in the build.