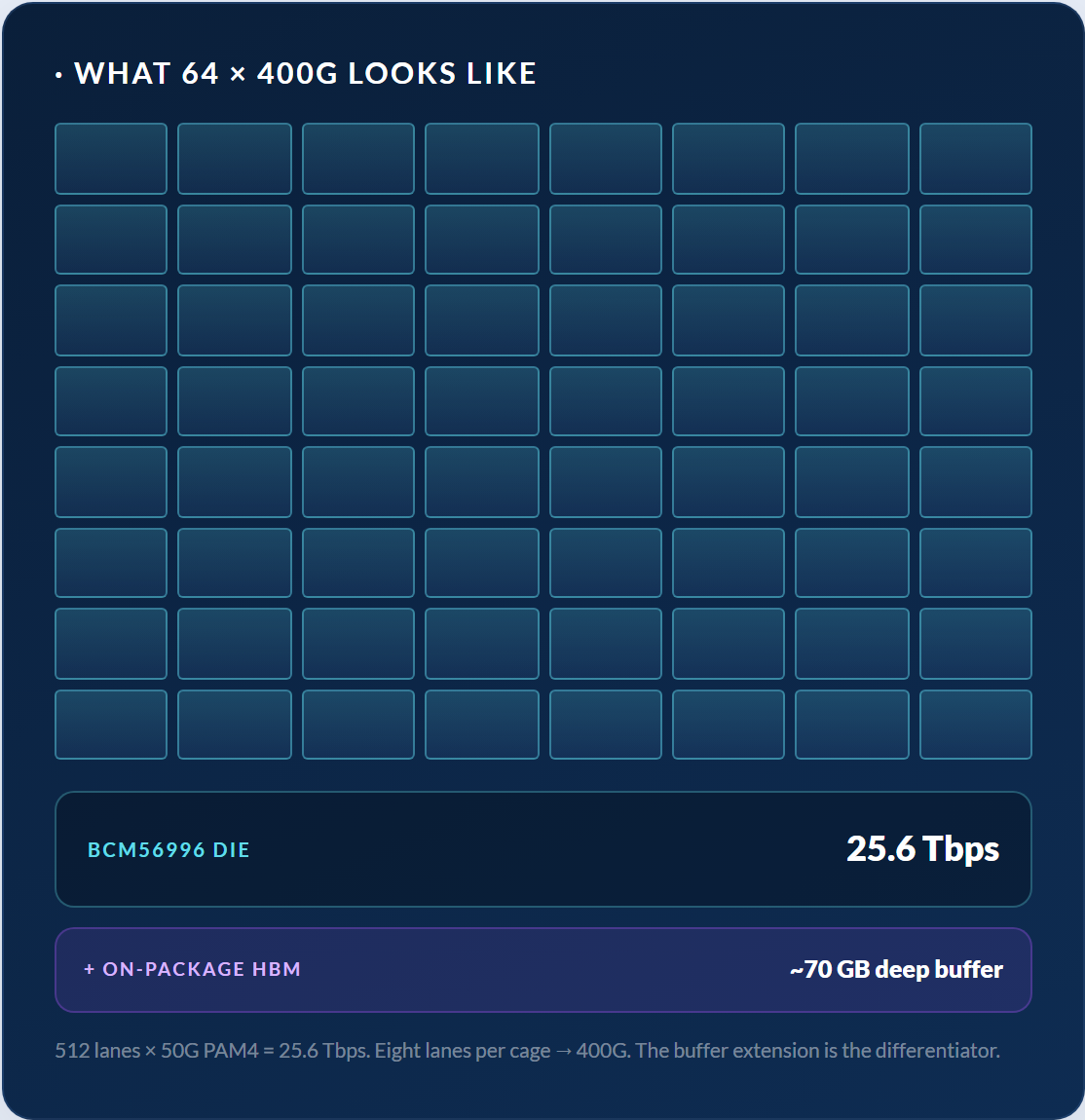
Edgecore· famille de plateformes DCS520
Fabric IA 400G à deep-buffer · DCI
AS9736-64D
Validé sur OcNOS-DC · ONIE préchargé
- Ports
- 64 × QSFP-DD (400G)Breakout : 2×200 / 4×100 / 8×50 (jusqu'à 256 ports logiques)
- Form
- 2RU · 21.5 kg
- Power
- ~2100 W typique · alimentation AC redondante hot-swap~33 W par cage QSFP-DD
- CPU
- Intel Xeon classe D · 4 Go de RAM
▌ À choisir lorsque
Fabric IA 400G pour les clusters GPU à pod unique où le deep buffer compte plus que les ports 800G, et pour les rôles d'agrégation 400G / DCI où la HBM absorbe les rafales que les commutateurs à plus petit buffer laissent tomber.