Edgecore· DCS520 플랫폼 제품군
딥 버퍼 400G AI 패브릭 · DCI
AS9736-64D
OcNOS-DC에서 검증됨 · ONIE 사전 탑재
- Ports
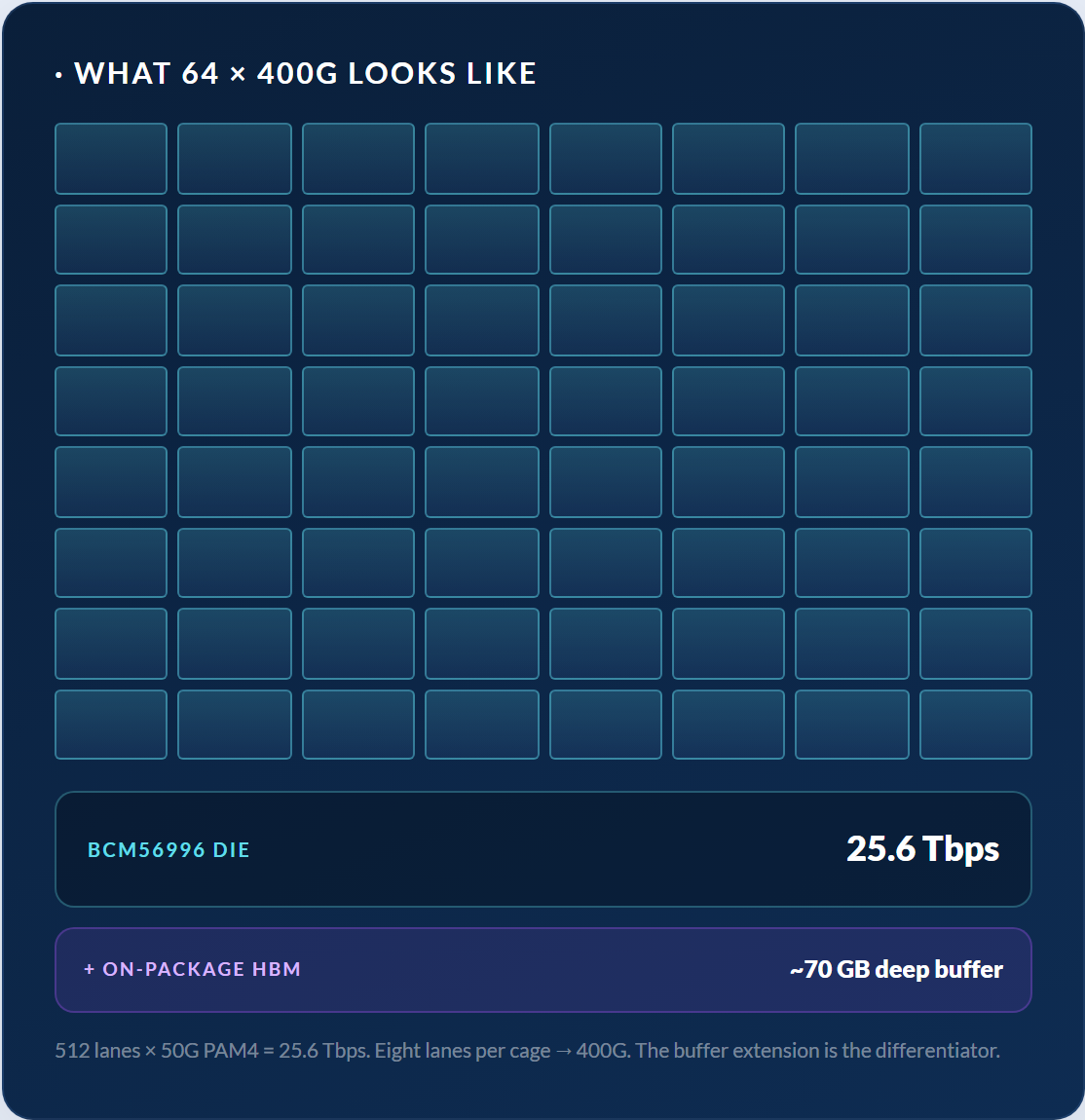
- 64 × QSFP-DD (400G)Breakout: 2×200 / 4×100 / 8×50 (최대 256개 논리 포트)
- Form
- 2RU · 21.5 kg
- Power
- 일반 ~2100 W · 핫스왑 이중화 ACQSFP-DD 케이지당 ~33 W
- CPU
- Intel Xeon D-class · 4 GB RAM
▌ 이럴 때 선택하세요
800G 포트보다 deep buffer가 더 중요한 single-pod GPU 클러스터를 위한 400G AI fabric용이며, 작은 버퍼의 switch가 드롭하는 버스트를 HBM이 흡수하는 400G 집선 / DCI 역할에도 적합합니다.