![]()
Open AI Networking
Deploy a high-performance, lossless 800G Ethernet fabric that maximizes the value of your AI investment.
Networking Stack for AI Factory
An AI Factory is a high-performance ecosystem where compute, storage, and networking work in perfect sync. The network serves as the central nervous system, crucial for maximizing efficiency and ROI. To accelerate Job Completion Time (JCT) and ensure high GPU utilization, a fine-tuned network fabric is essential.
As the “central nervous system” of your AI Factory, OcNOS provides the intelligent networking foundation you need to handle the most demanding workloads. The right network fabric is key to preventing bottlenecks and ensuring your massive hardware investments are fully utilized.
Accelerate Training Times
The right fabric provides the ultra-low latency and high throughput needed to significantly reduce Job Completion Time for complex AI models.
Enable Scalable Growth
A modern network architecture allows you to seamlessly add compute and storage resources, enabling a pay-as-you-grow model that scales to thousands of nodes.
Optimize Your Return on Investment
Eliminate wasted GPU cycles caused by network bottlenecks, ensuring your high-value hardware is always working at peak performance to maximize your business value.
“Partnering with IP Infusion to deploy OcNOS-DC has revolutionized our ability to deliver high-performance GPU-based services. The AI-optimized features, seamless orchestration integration, and disaggregated architecture allow us to scale efficiently while maintaining the low-latency, lossless connectivity our customers require for their AI/ML workloads.”
George Cvetanovski, Founder and CEO of HYPERSCALERS
The OcNOS Advantage
Proven performance, streamlined automation, and cost-effective scalability for your AI projects.
Engineered for Lossless AI Performance
OcNOS ensures lossless RoCEv2, ultra-low latency, and intelligent traffic prioritization, guaranteeing your AI models converge faster and your training times are reduced.
Your Path to Seamless Automation
With OcNOS comprehensive APIs (Netconf, gNMI, OpenConfig) and dedicated Ansible Collection, you can deploy and orchestrate your entire fabric with speed and consistency.
Carrier-Grade Reliability & Scale
Trusted by global service providers and data centers, OcNOS ensures your AI fabric remains agile and performs consistently as you scale to thousands of GPUs.
Cost Efficiency & Openness
Open architecture gives you the freedom to choose from the industry’s widest ecosystem of whitebox hardware and optics, enabling significant TCO reduction.
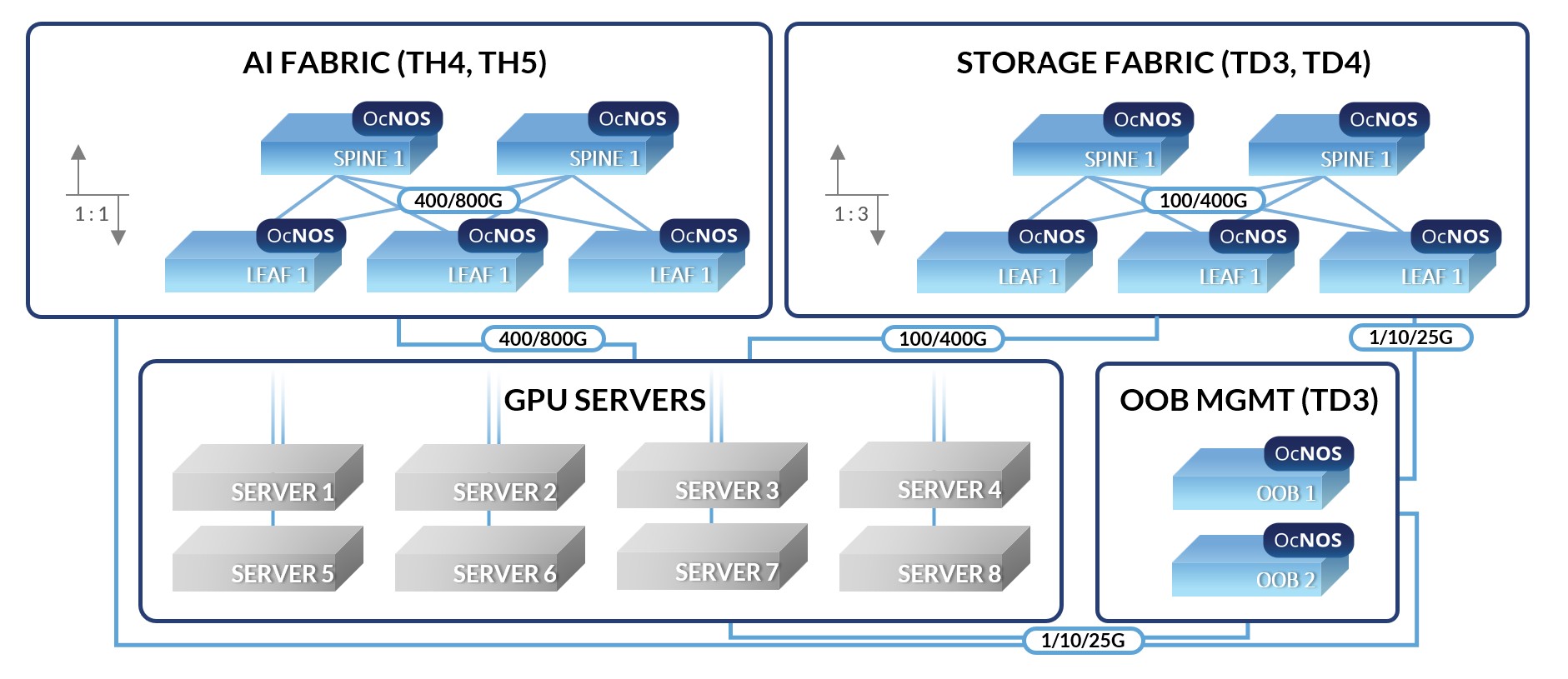
How OcNOS Creates a Lossless AI Fabric
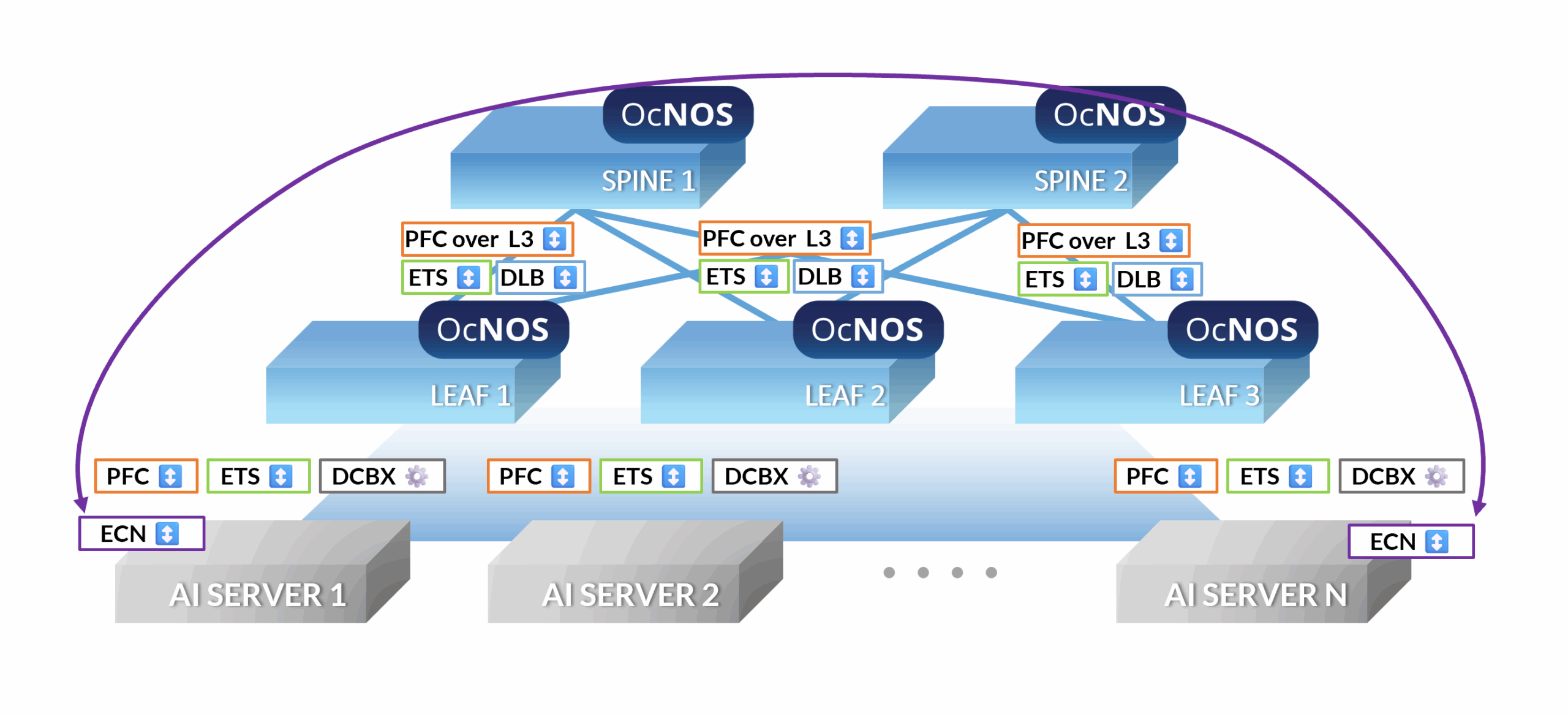
OcNOS: Orchestrating an End-to-End Lossless AI Fabric
RoCEv2 (RDMA over Converged Ethernet)
Priority Flow Control (PFC)
Explicit Congestion Notification (ECN)
Dynamic Load Balancing (DLB)
Enhanced Transmission Selection (ETS)
DCB Exchange Protocol (DCBX)
OcNOS 800G Switches
We’ve done the robust testing and validation, so you can choose from the industry’s best hardware with complete confidence.
Qualified 800G Optics
OcNOS offers the widest support for optics, ensuring every customer can select their preferred optics supplier.
Resources & Technical Documentation
Solution Briefs & White Papers
Solution Brief: OcNOS for AI Fabric
Discover the technical advantages of building a high-performance, lossless fabric for demanding AI/ML workloads with OcNOS.
White Paper: Migrating to Hybrid Cloud-Native Data Center
Learn the strategies and benefits of migrating to a modern, cloud-native architecture with an open networking foundation.
Solution Brief: 400G Upgrade for Data Centers with OcNOS
Discover how 400G switches with OcNOS save power, space, and cost while liberating data centers from scale limitations.
Solution Brief: Data Center Interconnect
Learn how to build scalable, high-performance connectivity between your data center locations with OcNOS DCI.
Product & Technical Documentation
OcNOS DC Feature Matrix
Explore the comprehensive list of protocols and features, including DCB, supported by the OcNOS Data Center platform.
Hardware Compatibility List
Browse the ecosystem of open, whitebox hardware platforms compatible with OcNOS, including 800G Tomahawk 5 switches.
Customer Stories & News
Press Release: IP Infusion to Showcase OcNOS Data Center for AI/ML Networking
IP Infusion will demonstrate its OcNOS Data Center networking operating system, optimized for Ethernet-based AI/ML data center fabrics, at the OCP APAC Summit 2025.
Case Study: Scott Data Deploys Network Disaggregation
Learn how Scott Data, a Tier III Certified data center, chose OcNOS for its comprehensive features and exceptional support.
Related Products
OcNOS Data Center
A carrier-grade NOS for your data center, with features for seamless operations and unmatched scalability.
Get Started Today!
Speak with an IP Infusion expert to discuss your specific needs and learn how we can help you unlock the full potential of your network with open networking solutions.