Introduction
IP Infusion’s OcNOS Data Center 6.6.1 release enables a powerful and high-performance Ethernet switch platform based on Broadcom’s Tomahawk 5 ASIC to meet the demanding needs of AI/ML data center fabrics.
As AI/ML training clusters scale exponentially, traditional switching solutions fall short in handling the intensive east-west traffic patterns and latency and packet loss sensitivity required by distributed GPU workloads.
OcNOS-DC 6.6.1 delivers Priority-based Flow Control (PFC) over Layer 3, Enhanced Transmission Selection (ETS), DCBX (Data Center Bridging Capabilities Exchange Protocol) and Dynamic Load Balancing (DLB) that work together in a cohesive manner to power high-throughput, latency-sensitive AI networks.
To assist AI orchestrator to optimize placement of AI/ML workloads across GPU server racks, OcNOS-DC exports real-time gNMI telemetry to orchestrators like Kubernetes that can allocate/reallocate jobs when network paths are overloaded. AI orchestrators can use Ansible to interact with OCNOS-DC to automate the process of reserving lossless queues, programming/reprogramming priority-to-traffic-class mapping, and activating dynamic load balancing on job specific links.
OcNOS-DC fully supports disaggregated open networking and provides cost-effective scaling with ONIE enabled Edgecore AIS800-64D and UfiSpace S9321-64E Tomahawk 5 whitebox switches and your choice of optics. Disaggregated networking makes AI data center buildouts more agile and provides competitive bidding and component-level price tracking.
AI/ML Data Center Networks With Dedicated Compute and Storage Fabrics
The performance requirements of modern AI/ML workloads are pushing towards a dedicated network for GPU-to-GPU communication. AI/ML training is incredibly sensitive to latency and packet loss.
Separating the high-performance GPU-to-GPU communication from other traffic (storage I/O, management, general IT) ensures that the critical training runs are not impacted by bursts or congestion from other workloads.
Each of the GPU-to-GPU and CPU-to-Storage fabrics can be purpose-built and tuned for its specific demands. The GPU-to-GPU fabric focuses on ultra-low latency, high bandwidth, and lossless transport. The storage fabric can be optimized for high throughput and large block transfers. The management fabric can be simpler, focusing on reliability and standard protocols.
Separate fabrics or networks allow independent scaling of compute, storage, and management resources. You can add more GPUs and network capacity to the GPU fabric without necessarily overbuilding your storage or management networks.
Typical Setup:
Compute Fabric (GPU-to-GPU): Very high-speed Ethernet using RoCEv2 with 400 GbE GPU interfaces and 800 GbE inter-switch fabric links.
Storage Fabric (CPU-to-Storage): Typically high-speed Ethernet with 100GbE CPU and storage interfaces using standard TCP/IP or sometimes RoCEv2 if low-latency storage access is paramount (e.g., for NVMe-oF).
Management Fabric: Standard Ethernet using copper 1GbE out-of-band management connectivity for SSH, telemetry, job scheduling, etc.
IP Infusion offers a comprehensive line of OcNOS-DC enabled multi-vendor data center switching platforms for each of the compute, storage and management fabrics. In the AI/ML data center network example shown in Fig. 1, the AI compute fabric is comprised of Broadcom Tomahawk 5-based switches, and the storage fabric is comprised of Broadcom Trident 3-X7-based switches, while Broadcom Trident 3-X2-based switches are used for out-of-band device management.
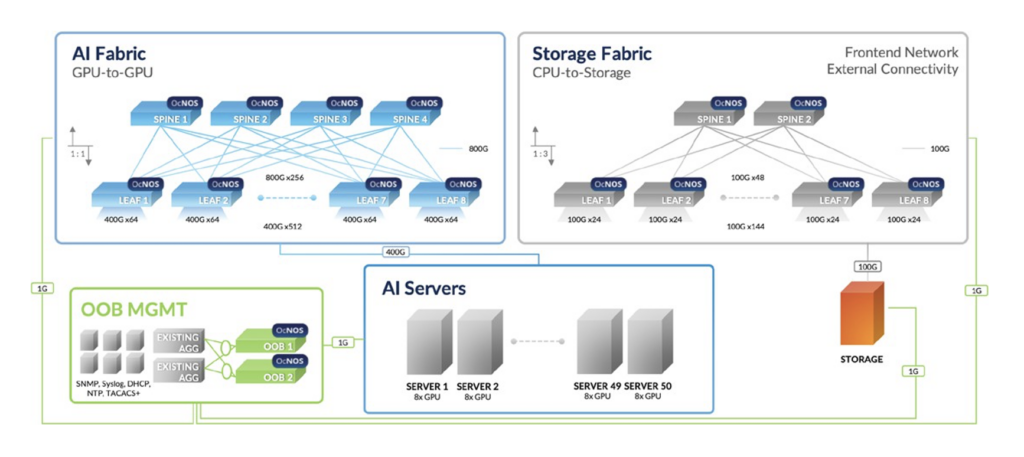
Fig. 1 Example: AI/ML Data Center Network Setup Supporting Up To 512 GPUs
Highlights of New ODM Hardware Platforms
OcNOS 6.6.1 supports the following new Broadcom Tomahawk 5-based ODM platforms in 2 RU form factor. With each additional hardware platform, IP Infusion further increases the advantages of its disaggregated solution for data center customers by offering options of different whitebox platforms to manage cost, lead time, and supply-chain challenges.
Edgecore AIS800-64D
The AIS800-64D is equipped with:
- 64 QSFP-DD 800 ports, each supporting 1 x 800 GbE (100G PAM4), or via breakout cables 2 x 400G GbE, 4 x200 GbE, or 8 x 100 GbE
- Up to 30W power budget per QSFP-DD 800 port
- 1 x RJ-45 serial console
- 1 x RJ-45 1000 BASE-T management
- 2 x SFP28 25G In-band management
- 1 x USB 3.0 storage port
- Broadcom Tomahawk 5 switching silicon
- 51.2 Tbps switching capacity
- Processor: Intel® Xeon® Processor D-1713NTE 4-Core 2.2 GHz
- BMC module with serial-over-LAN support
- e-fuses to protect transceivers and internal components
- Supports hot/cold aisles with front-to-back/AFO/port intake airflow SKU and back-to-front/AFI/port exhaust airflow SKU
- Hot-swappable, load-sharing, redundant 3000 W AC/DC PSUs
- 4 Hot-swappable fan modules with 7+1 redundant fans
AIS800-64D front panel view:

UfiSpace S9321-64E
The S9321-64E is equipped with:
- 64 x 200/400/800G QSFP-DD ports
- 2 x 10/25G SFP28 ports
- 1 x 100/1000M RJ45 OOB management port
- 1 x RJ45 & Micro USB serial console port
- 1 x USB 3.0 Type-A port
- Broadcom Tomahawk 5 switching silicon
- 51.2 Tbps switching capacity
- Intel Icelake-D 4-Core @ 1.9GHz
- Individual BMC for monitoring and managing equipment health status
- Hot swappable power supplies with 1+1 redundancy support
- Hot swappable fan modules with 3+1 redundancy support
S9321-64E front panel view:

Detailed information on the OcNOS 6.6.1 data center features and overall data center platforms are available in our Feature Matrix here.
Key Features & Capabilities
AI/ML workloads are comprised of multiple traffic types with the overall make-up changing dynamically. As shown in Table 1, inference, control, gradient synchronization, and activation and feature map data traffic types are extremely sensitive to latency, bandwidth, and packet loss. Any compromise in these areas directly translates to increased Job Completion Time (JCT), reduced GPU utilization and training instability. These traffic types are best transported by dedicated GPU-to-GPU fabric.
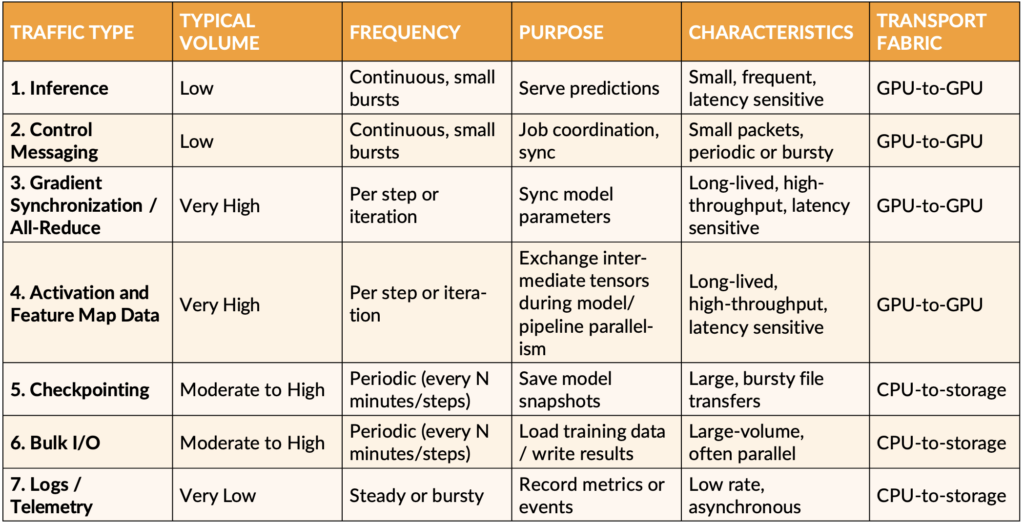
Table 1: AI/ML Workload Traffic Types
Ensuring proper transport performance for all traffic types of varying characteristics and sensitivity to loss and latency shown in Table 1 requires advanced traffic engineering support in the respective fabric handling the traffic types.
OcNOS-DC 6.6.1 delivers a suite of traffic engineering features including PFC over Layer 3, ETS, DCBX, ECN, and DLB to accelerate large-scale workloads in a distributed and bandwidth-intensive AI infrastructure. OcNOS-DC 6.6.1 combines the stability and scalability of Layer 3 with the lossless performance and dynamic responsiveness required by AI/ML clusters.
PFC (Priority-based Flow Control) over Layer 3
PFC over Layer 3 enables lossless Ethernet transport across Layer 3 spine-leaf topology-based CLOS fabrics—essential for L3 routed AI workloads using RoCEv2 (RDMA over Converged Ethernet v2) like the gradient synchronization, and activation and feature map data traffic types.
PFC (IEEE 802.1 Qbb) is a link-level mechanism that provides lossless transport for specific traffic classes (e.g., RoCEv2) by pausing transmission of specific priorities on a link to prevent packet loss. PFC is a Layer 2 mechanism — it only works between directly connected neighbors on an Ethernet link. On a typical IP-routed (L3) network, PFC by itself can’t operate end-to-end. However, when the packet is routed hop-by-hop at L3, the actual transmission on each link is L2. Therefore, PFC can still apply at each hop, controlling traffic for a given priority (e.g., for CoS 3 used by RoCEv2). The end result is that lossless behavior is preserved link-by-link provided all hops agree on which priorities to pause, even though the overall path is routed.
ETS (Enhanced Transmission Selection)
ETS is a traffic management mechanism defined in the Data Center Bridging (DCB) suite (IEEE 802.1Qaz). It allows bandwidth on a shared Ethernet link to be allocated among different traffic classes (TCs), ensuring that multiple traffic types of AI/ML workloads shown in Table 1 can coexist in their respective fabric without starving each other. Ethernet frames are classified into priority groups (0–7) using CoS (Class of Service) bits in the VLAN tag. These priorities are mapped to Traffic Classes (TCs) on the switch. ETS assigns a percentage of link bandwidth to each TC using strict priority (SP) or weighted round robin (WRR) scheduling. If a TC uses less than its allocated bandwidth, the excess can be used by others (fair-sharing).
ETS ensures that all traffic types of AI/ML get priority treatment with fair bandwidth access. Example ETS Config:
- TC0 (best-effort): 30% bandwidth, priorities 0,1,2
- TC1 (lossless): 70% bandwidth, priorities 3,4
DCBX (Data Center Bridging Capabilities Exchange Protocol)
DCBX is used to negotiate and enforce PFC + ETS settings at every L2 link, enabling hop-by-hop lossless transport of selected L3-over-Ethernet traffic (e.g., RoCEv2) in a routed network.
DCBX negotiates PFC:
- Which IEEE 802.1p priorities (0–7) have PFC enabled
- Ensures both ends of a link agree on PFC settings
Example: Priority 3 is enabled for RoCEv2.
DCBX negotiates and distributes ETS (Enhanced Transmission Selection) settings:
- How much bandwidth each traffic class gets (e.g., lossless vs best-effort)
- How priorities map to traffic classes (TCs)
This ensures that every switch and NIC along the path reserves consistent bandwidth and maps CoS values to queues the same way.
DCBX sets application priority mapping
- What traffic (e.g., udp port 4791) belongs to which priority (e.g., Priority 3)
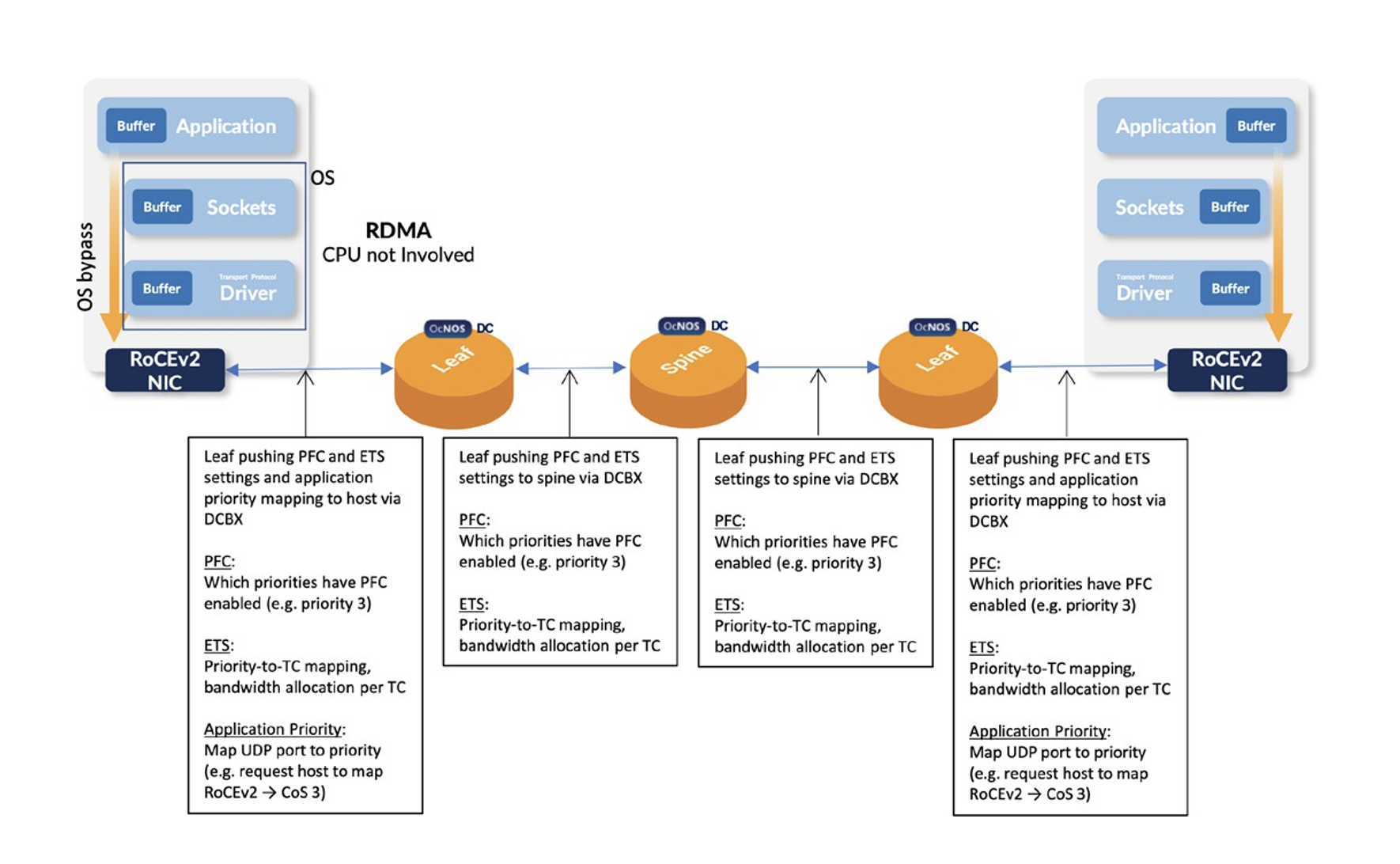
Fig. 2: Each L2 Segment Made Lossless via PFC, Configured via DCBX, for A L3 Flow
Through automated negotiation of traffic classes and bandwidth allocation across directly connected Ethernet devices at each hop, DCBX ensures consistent QoS, workload isolation, and traffic prioritization end-to-end – no misconfigured bandwidth or pause behavior.
ECN (Explicit Congestion Notification)
ECN allows congestion to be signaled without dropping packets. Instead of using packet drops as congestion signal in traditional TCP/IP congestion control, ECN enables early detection of congestion in switches, so endpoints can react before packet loss occurs. Devices with ECN enabled mark packets (set a bit in the ECN field in the DSCP byte in the IP header) instead of dropping them when congestion is starting (queue buildup), allowing lossless feedback.
If a switch experiences emerging congestion for a traffic class, it marks the ECN field of packets of the traffic class instead of dropping them. The RoCEv2 receiver sees the ECN mark and signals the sender by sending a Congestion Notification Packet (CNP) to sender. The RoCEv2 sender, upon receiving the CNP, reacts by throttling the transmit rate and maintaining a cool-down interval. If no further CNPs arrive, the sender may gradually resume full-speed transmission.
The following table summarizes the purpose of PFC, ETS and ECN, what they operate on, and the standard that defines their function.

Table 2: Purpose, Where Used and Standard for PFC, ETS and ECN.
AI/ML Workload QoS Setting
An example of QoS setting for each AI/ML traffic type is shown in the following table by each of compute and storage fabrics.
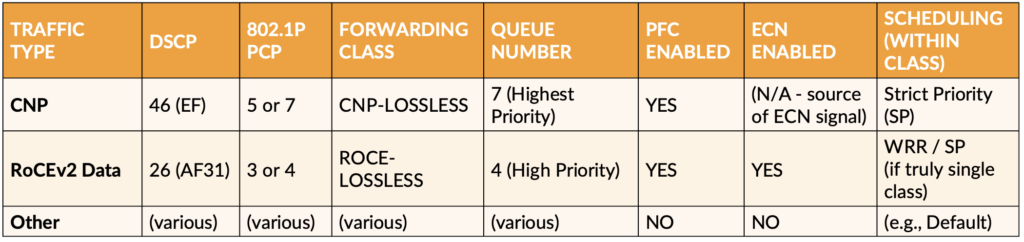
Table 3: QoS Setting Example of AI/ML Workload Traffic Types in GPU-to-GPU Fabric
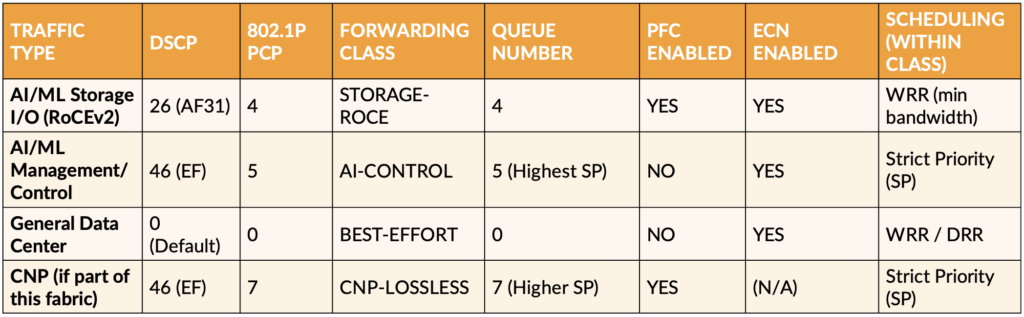
Table 4: QoS Setting Example for AI/ML Workload Traffic Types in Storage Fabric
DLB (Dynamic Load Balancing)
Traditional ECMP uses a static hash function (e.g. 5-tuple: src/dst IP, ports, protocol) to pick an egress link from the ECMP group (i.e. the next hops for a given destination prefix). This does not account for actual link utilization or congestion. Long lasting heavy elephant flows like AI/ML gradient synchronization traffic may be concentrating in a few hash buckets while others are underutilized. Static hashing also lacks flexibility and does not respond to changing link conditions (e.g., congestion, link failures, or utilization spikes).
DLB maximizes utilization across ECMP and LAG paths using flowlet-aware rebalancing to prevent hot spots. DLB replaces static hash with a dynamic index when selecting an egress link from the ECMP group for a destination prefix. The dynamic index adjusts based on link utilization, queue depth, packet drops and LAG/ECMP member availability. Change of output link for a flow only takes effect for a new flowlet to preserve in-order delivery.
Summary:
IP Infusion’s OcNOS-DC 6.6.1 introduces a powerful data center switching solution optimized for AI/ML workloads using Broadcom Tomahawk 5-based whitebox switches. Designed for high-performance GPU-to-GPU fabrics, the release delivers critical traffic engineering features—PFC over Layer 3, ETS, DCBX, ECN, andDLB—to support RoCEv2 with high throughput, low latency and lossless transport. The solution is tailored for AI/ML traffic patterns such as inference, gradient synchronization, and feature map exchanges, offering differentiated QoS per workload traffic type using advanced scheduling, prioritization, and congestion signaling mechanisms.
The overall network architecture separates GPU-to-GPU, storage, and management networks to ensure dedicated and tuned performance per traffic type.
OcNOS-DC supports disaggregated networking, enabling flexibility and cost control using open, ONIE- enabled switches from Edgecore and UfiSpace. Real-time gNMI telemetry and Ansible-based automation help AI orchestrators (e.g., Kubernetes) optimize workload placement and network configuration dynamically.
Available in June 2025, this release positions OcNOS-DC as a key enabler of scalable, agile, and efficient AI data center fabrics with open networking support.
Contact Us to explore OcNOS solutions for data center.

Alan Huang is the Senior Product Manager, Data Center for IP Infusion.