The AI revolution is driving unprecedented demand for network performance. As organizations build clusters containing hundreds or even thousands of GPUs, the network has become a critical determinant of AI application performance, infrastructure utilization, and overall return on investment.
Yet many discussions around AI networking focus solely on speeds and feeds—800G interfaces, switching capacity, and bandwidth. While these capabilities are essential, they are only part of the story.
The real challenge is transforming the network from a simple connectivity layer into an intelligent infrastructure platform capable of supporting AI workloads at scale.
This is the journey from connectivity to AI infrastructure intelligence.
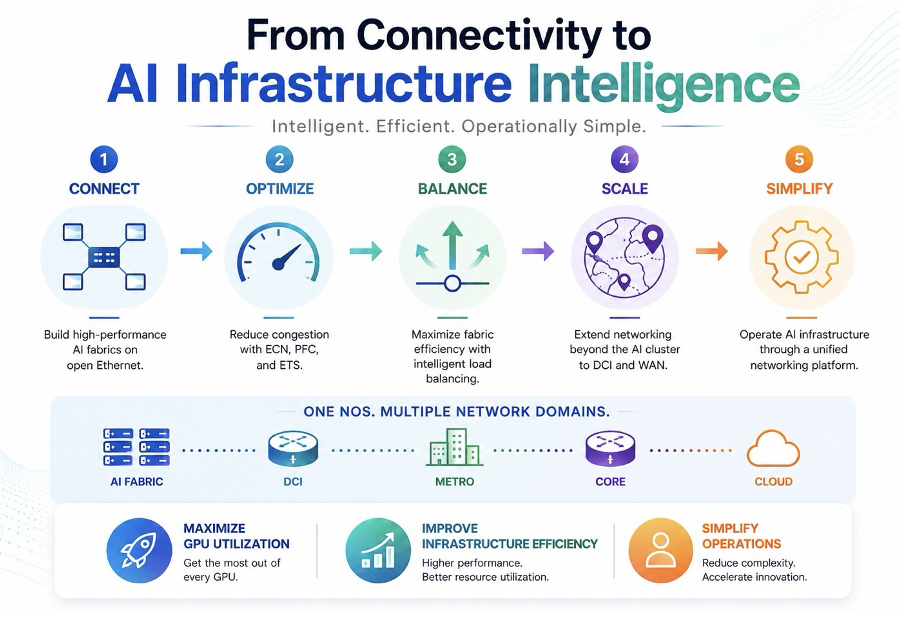
Stage 1: Connecting the AI Cluster
For decades, Ethernet has been the foundation of data center networking. Its openness, scalability, and economics have made it the dominant networking technology across enterprise, cloud, and service provider environments.
AI workloads, however, place new demands on the network.
Large-scale model training and distributed inference generate massive east-west traffic patterns, frequent all-to-all communications, and highly synchronized workloads that can overwhelm traditional networking approaches.
In the AI era, connectivity alone is no longer enough.
The network must actively contribute to application performance.
Stage 2: Building a Lossless Foundation
Modern AI workloads rely heavily on efficient GPU-to-GPU communication. Even small amounts of packet loss can introduce retransmissions, increase latency, and reduce overall cluster efficiency.
The first step toward an AI-optimized fabric is creating a congestion-aware, loss-minimized network.
OcNOS enables this through advanced traffic management capabilities such as:
- Explicit Congestion Notification (ECN)
- Priority Flow Control (PFC)
- Enhanced Transmission Selection (ETS)
Together, these technologies help the network proactively manage congestion while ensuring critical AI traffic receives the resources it needs.
The result is a high-performance Ethernet fabric capable of supporting demanding AI workloads without sacrificing openness or flexibility.
Stage 3: Optimizing Traffic Flow
As AI clusters grow, traffic patterns become increasingly dynamic.
Temporary hotspots can emerge during training operations. Certain paths may become congested while others remain underutilized. Static traffic distribution mechanisms are often unable to adapt quickly enough to changing workload demands.
To address this challenge, OcNOS introduces intelligent traffic optimization through:
- ダイナミックロードバランシング
- Global Load Balancing
By continuously distributing traffic across available paths and adapting to real-time network conditions, the fabric can better utilize available bandwidth and reduce congestion-related bottlenecks.
The network evolves from a passive transport layer into an active participant in workload optimization.
Stage 4: From Network Intelligence to Infrastructure Intelligence
The next phase of AI networking extends beyond the boundaries of the data center fabric.
AI infrastructure does not operate in isolation.
Organizations must connect AI clusters to:
- Data center interconnect (DCI) networks
- Enterprise infrastructure
- Cloud environments
- Regional and national backbones
As AI deployments scale, operational consistency becomes just as important as raw network performance.
Managing multiple network operating systems across AI fabrics, DCI environments, and WAN infrastructure introduces complexity, increases operational overhead, and slows innovation.
This is where a unified networking strategy becomes essential.
Stage 5: Simplifying AI Operations
Building an AI cluster is challenging.
Operating AI infrastructure at scale is even harder.
Network teams must deploy, monitor, troubleshoot, upgrade, and secure increasingly complex environments while ensuring uninterrupted application performance.
Rather than managing separate software stacks for AI fabrics, DCI, and transport networks, organizations can benefit from a common operational model spanning the entire infrastructure.
OcNOS enables operators to leverage a consistent software architecture across multiple network domains, helping reduce operational complexity while accelerating deployment and simplifying lifecycle management.
The result is a networking foundation that scales with the business—not just the cluster.
The Future of AI Infrastructure
The future of AI networking is not simply about building faster fabrics.
It is about creating intelligent, efficient, and operationally simple infrastructure capable of supporting the full AI lifecycle.
By combining congestion-aware traffic management, intelligent load balancing, and a unified operational model, OcNOS transforms Ethernet from a connectivity layer into a strategic platform for AI infrastructure.
Because in the AI era, success will not be determined solely by how many GPUs an organization deploys.
It will be determined by how effectively the entire infrastructure works together to unlock their full potential.

Rishi Narain is the Vice President of Product Management for IP Infusion.